
openai에서 ChatGPT를 기반으로
새로운 애플리케이션을 개발하거나
통합할 수 있도록 API(Application Programming Interface)를 제공합니다.
python을 설치했다는 가정 하에 진행됩니다.
설치하지 않으신 분들은 아래 사진을 클릭하여
설치를 진행해주신 뒤 따라해주세요

pip install openai
우선 터미널을 실행시킨 뒤
chatgpt의 openai의 모듈을 다운로드 받아줍니다.
openai에서 모듈을 사용하기 위해서는
api_key를 발급 받아야 합니다.
ChatGPT OpenAI API 키 발급 받기

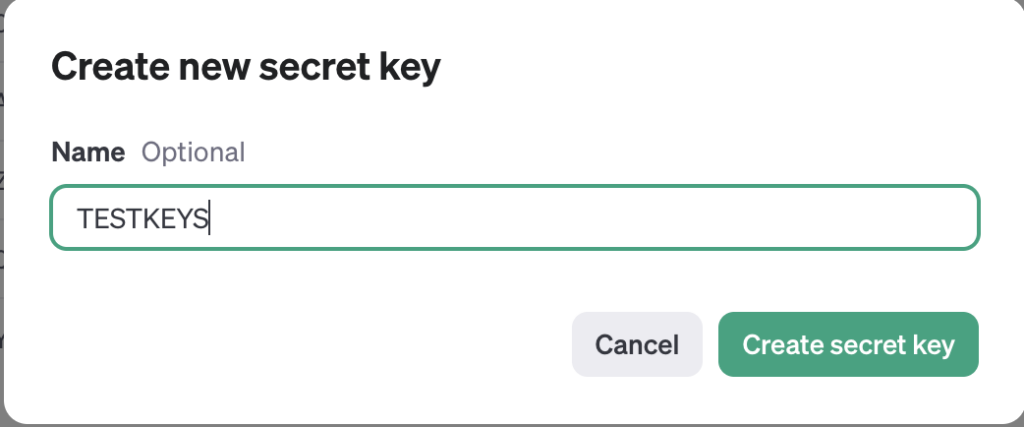
키의 이름을 설정
키의 이름은
프로젝트 이름 혹은 어디에 이 키를 사용하는지를 명시해 둡니다.
추후 어떤 키인지 알아야할 경우가 있을 수 있습니다.
저는 우선 블로그의 테스트를 위해 API key를 발급 받는 것이기 때문에
TESTKEYS라는 이름으로 키를 만들도록 하겠습니다.
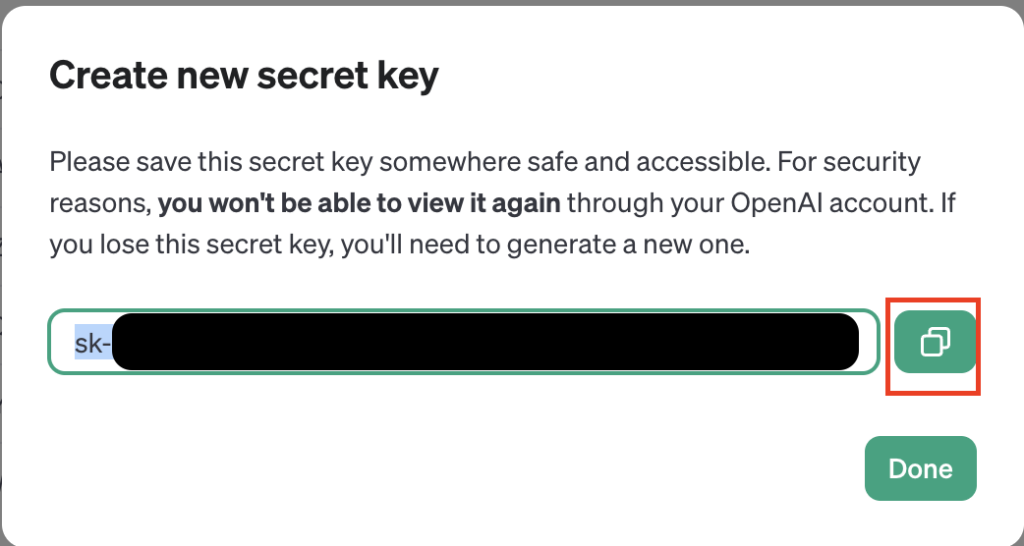
아래와 같은 sk-로 시작하는 키값이 나옵니다.
이를 빨간색 강조 표시된 내용을 클릭하여 복사를 진행합니다.
Done을 눌러 키 발급을 마칩니다.
ChatGPT 튜토리얼 따라하기
파이썬 가상환경 설정
python에서는
각 모듈이 여러가지 버전이 필요할 수 있으므로
가상화로 각각의 파일의 버전을 관리합니다.
cmd 혹은 명령창에서 아래 코드를 실행하면
python3 -m venv .venv
.venv라는 폴더가 만들어지면서
가상화를 실행시킬 수 있습니다.
가상화 실행시키기
MacOS / Linux
source .venv/bin/activate
Windows
.venv\Scripts\activate
환경변수 관리
아래 명령창을 실행합니다.
명령창에서 touch는 파일을 만든다라는 의미이고
파일명이 .env라는 파일을 만듭니다.
touch .env
이 파일은 python의 디셔터리와 비슷한 형태로
‘키 = 값’ 형식으로 구성합니다.

.env 파일이 생성되었으니
vscode에서 .env를 클릭하여 편집합니다.
# Once you add your API key below, make sure to not share it with anyone! The API key should remain private. OPENAI_API_KEY=API Key 입력

.env를 사용하기 위해 dotenv를 사용할 것입니다.
[Chatgpt API를 파일에 두지 않기 위해 .env를 사용합니다]
이러한 api 키의 경우 노출이 된다면
다른 사람의 요청을 실행할 수 있게 되기 때문에
노출되지 않도록 주의하여야 합니다.
github에 올리거나 할 경우도
.env파일은 gitignore에 적용해두어야 합니다.
pip install python-dotenv
OpenAPI Quickstart
내용 중 예시를 실행시키기 위해
dotenv의 load_dotenv를 임포트 해줍니다.
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
# defaults to getting the key using os.environ.get("OPENAI_API_KEY")
# if you saved the key under a different environment variable name, you can do something like:
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a poetic assistant, skilled in explaining complex programming concepts with creative flair."},
{"role": "user", "content": "Compose a poem that explains the concept of recursion in programming."}
]
)
print(completion.choices[0].message)파일 구성은 아래와 같습니다.

ChatGPT 기본 질문
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
temperature = 1,
top_p=1,
presence_penalty=1,
frequency_penalty=1,
n=1,
max_tokens=4000,
stop=None
)
print(completion.choices[0].message)
각각 어떤 것을 의미하는 것인지 이야기해보겠습니다.
model(모델)
사용할 언어 모델을 지정합니다.
현재(2023-12-13)기준 사용 가능한 모델은 아래와 같습니다.

message(메세지)
사용자가 입력할 프롬프트가 포함된 리스트
role(역할)과 content(문장)로 나뉩니다.
역할 부여하거나 이어서 질문하는 방법
messages=[
{“role”: “system”, “content”: “You are a helpful assistant.”}
role:system은 역할 부여를 의미합니다.
{“role”: “user”, “content”: “Hello!”}
role : user는 우리가 AI에게 하고싶은 말을 적는 곳 입니다.
{“role”: “assistant”, “content”: “What can i do for you?”}
role : assistant 의 content 내용은 이전 답변과 이어진 이야기를 하고 싶을 때 gpt의 대답을 적어두는 것입니다.
이전 내용을 기준으로 대화를 하고싶은 경우 user와 assistant를 번갈아가며 사용할 수 있습니다.
]
temperature(온도조절)
텍스트의 랜덤성(무작위성)과 관련된 파라미터
온도를 높게 설정하면 [최대값 2.0]
모델이 생성하는 텍스트가 예측에 벗어나보여 창의적인 경향을 띔
온도를 낮게 설정하면
전형적이고 보수적인 텍스트를 생성하는 경향을 보임
일반적으로 0.5 ~ 1.5 사이의 값을 시작점으로 사용
프롬프트에 따라 다르므로 실험적으로 찾는 것이 좋음
설정값 범위 : 0.0 ~ 2.0
기본값 : 1
top_p(핵 샘플링)
토큰이 샘플링되는 범위를 제어
응답 생성시 모델은 다음 토큰의 어휘에 대하여 확률분포를 계산함
top_p가 0.7이면 누적 확률이 0.7보다 상위 토큰 중에서만 다음 토큰을 샘플링 함
1.0으로 설정시 모든 토큰에서 샘플링하고
0.0으로 설정하면 항상 가장 확률이 높은 단일 토큰을 선택함
설정값의 범위 : 0.0 ~ 1.0
기본값 : 1
presence_penalty(존재 패널티)
단어가 이미 생성된 텍스트에 나타난 경우 해당 단어가 등장할 가능성을 줄임
빈도수 패널티와는 달리 과거 예측에서 단어가 나타나는 빈도수에 따라 달라지지는 않음
존재 패널티의 값을 크게 설정하면 모델이 새로운 주제에 이야기할 가능성이 높아짐
설정값 범위 : 0.0 ~ 2.0
기본값 : 1
frequency_penalty(빈도수 페널티)
모델이 동일한 단어를 반복적으로 생성하지 않도록 설정
어떤 단어가 어느 빈도로 등장 했는지에 영향을 받음
모델이 이미 생성한 단어를 다시 생성하는 것을 자제함으로
중복되지 않은 단어의 생성을 유도할 수 있음
모델이 특정 단어를 반복하는 경향을 보이면 빈도수 페널티 값을 높게 설정
설정값 범위 : 0.0 ~ 2.0
기본값 : 0
n(응답 개수)
입력 메시지에 대해 생성할 답변 수를 설정합니다.
기본값 : 1
max_tokens(최대 토큰)
최대 토큰 수를 제한합니다.
API 사용은 토큰 수에 따라 요금이 부과되므로
최대 토큰 파라미터를 통해 답변의 길이를 조절할 수 있습니다.
값을 설정하지 않으면 모델의 최대 토큰에 맞춰 설정됩니다.
stop(중지문자)
토큰 생성을 중지하는 문자로
sotp=[‘\n’, ‘ ‘]처럼 문자열 목록으로 값을 설정합니다.
None으로 설정하면 따로 중지 문자 설정을 하지 않고 끝까지 생성